工业互联网实时计算引擎
工业互联网实时计算引擎
计算引擎
计算引擎包括平台计算引擎和边缘计算引擎。
边缘计算引擎运行在边缘,负责在边缘侧进行数据初步转换计算。
平台计算引擎是充分利用平台资源优势,与平台结合,负责平台上所有数据的大数据分析,既可以处理实时数据又可以批处理的数据引擎。
边缘计算与平台计算协同,实现工业互联网平台的数据实时,快速,有效处理,助力平台应用快速发展。本文的调研对象为平台计算引擎。
计算的必要性
工业互联网平台由三层部分组成。上层SaasS 工业业务应用,中间PaaS工业平台,底层边缘和设备。 数据做为基本要素,从设备上采集到数据,然后传输到中间PaaS工业平台进行计算,存储,上层利用数据服务构建应用。数据的计算贯穿在整体平台。
平台计算目的:
- 实现对设备时序数据和属性数据的处理与计算
- 实现对报警规则的处理与计算
- 实现SaaS平台对数据展示和应用的处理与计算。
计算的要求:
- 流处理,就是对源源不断的数据流进行处理;
- 批处理,就是对一定规模量的数据进行计算。
流处理要求更高的实时性,批处理则主要在数据处理规模上发力。
计算引擎的调研与选型
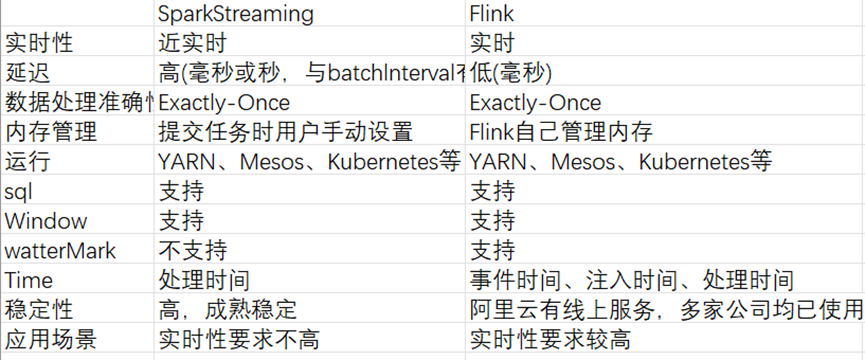
计算引擎必须满足大数据量的批量计算,还需要支持低延时的流式计算。目前大数据领域计算引擎有两类:Spark Streaming, Flink。
引擎对比
部署
Spark 部署支持三类模式:本机模式,伪分布式模式,Spark On yarn Flink部署支持三类模式: 本地模式,Standalone模式,Flink On yarn 与Hadoop关系及扩展 无论Spark 和Flink均与Hadoop天然结合,但为了减少Hadoop的关联,只部署Hadoop最小3台机器。
选用Flink On Yarn 部署方式,即可以满足Flink的要求,同时后期扩展使用Spark On yarn
引擎机制与功能特点
Spark Streaming
Spark Streaming是Spark最早推出的流处理组件,它基于流式批处理引擎,基本原理是把输入数据以某一时间间隔批量的处理(微批次),当批处理时间间隔缩短到秒级时,便可以用于实时数据流。
编程模型 在Spark Streaming内部,将接收到数据流按照一定的时间间隔进行切分,然后交给Spark引擎处理,最终得到一个个微批的处理结果。
数据抽象 离散数据流或者数据流是Spark Streaming提供的基本抽象。它可以是从数据源不断流入的,也可以是从一个数据流转换而来的。本质上就是一系列的RDD。每个流中的RDD包含了一个特定时间间隔内的数据集合,如下图所示。
窗口操作 Spark Streaming提供了滑动窗口接口,滑动窗口的两个重要的参数是窗口大小,滑动步长。它允许在数据的滑动窗口上应用转换。如下图所示,每当窗口在源Dstream上滑动时,位于窗口内的源RDDs就会被合并操作,来生成窗口化的Dstream的RDDs。
Flink
Spark Streaming是基于批处理引擎的,因此它的处理延时较大,基本上为秒级延迟。Flink从2014年12月成为Apache的顶级项目。Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink的特点是低延迟、高吞吐和一致性(结果的准确和良好的容错性)。
编程模型 在Flink中,流也被分成两类:无界流和有界限,分别对应着Flink中的流处理场景和批处理场景。 无界流:有开始无结束的数据流; 有界流:有开始也有结束的数据流,批处理被抽象成有界流;
窗口类型 Flink中提供了三种窗口计算类型:滚动窗口、滑动窗口和会话窗口。
滚动窗口是将每个元素分配给具有指定窗口大小的窗口。滚动窗口有固定大小,而且不会互相重叠。一个窗口的结束意味着另一个窗口的开始。
滑动窗口将元素分配到固定长度的窗口,类似于滚动窗口的分配。窗口大小由窗口大小参数配置。滑动步长控制滑动窗口启动的频率,如果滑动步长小于窗口大小,则滑动窗口会有重叠。
会话窗口:会话窗口根据会话间隔进行窗口的划分,与滑动和滚动窗口相比,会话窗口没有重叠,也没有固定的开始和结束时间。
- 时间语义 Flink提供了三种时间语义,分别是事件时间、注入时间和处理时间。 事件时间即为事件发生的时间; 注入时间是指数据从数据源进入数据处理引擎的时间; 处理时间是真正进行数据处理的任务运行的机器时间。 watermark机制 Flink在事件时间应用程序中使用水印来判断时间。水印也是一种灵活的机制,以权衡结果的延迟和完整性。
对比